这两天看了YOLO_V1的东西,自己复述了一下主要的过程,并记一下自己容易弄混的几个地方。
参考资料
YOLOv1的原理及实现过程
YOLOv1论文理解
【深度学习YOLO V1】深刻解读YOLO V1(图解)
B站视频讲解
PPT参考(下面图都来自PPT)
论文地址(还没看)
源码分析(还没看)
复述和总结
YOLO_V1就是一个单独的网络,是one-stage的过程,不像Faster-RCNN那样的需要先把region proposal找出来。
Training过程
YOLO_V1在训练的时候是把一张图片分成SxS个网格(cell),每个cell有B个bounding box,一共检测C个类别。假设S=7,B=2,C=20,那么一张图片就有98个bbox。每个box在training之后输出五个值(x,y,w,h,c):
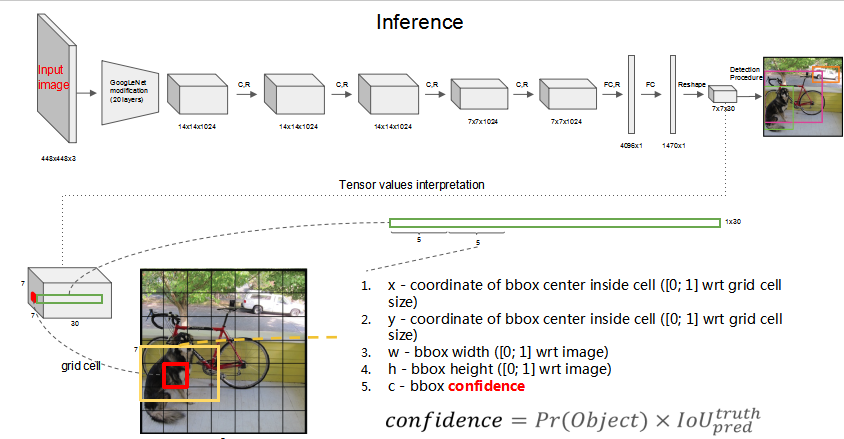
(x,y)是这个bbox的中心点坐标,相对它所属cell的左上角顶点坐标而言的。(w,h)是这个bbox的宽高,是相对整个图片的宽高的比例,c是confidence,包含两个方面,一个是有目标的概率,用Pre(Object)表示,另一个表征这个box预测的位置有多准,用IOU值来表示。两个相乘得到置信度c。
在training阶段最后得到的是7x7x30的向量,注意training阶段没有进行NMS的过程,那是testing阶段做的事。7x7就是49个cell,每个cell有30个数(2x5+20),20是这个cell属于20个类别的可能性,这个概率值是在各个边界框置信度下的条件概率。
这里很重要的一点不管一个cell预测多少个边界框,其只预测一组类别概率值,也就是说只对每一个cell预测一组(C个)类概率,而不考虑边界框的个数,所以每个单元格最后只是输出一组类概率,而不是每个边界框一组,所以最后每个cell里的bbox只检测同一个物体。这里我想了很久,后来是看B站视频讲解弄懂的,记在了后面几个问题里面。
LOSS部分(精华)
YOLO_V1其实是回归问题,输出的是bbox的坐标,所以采用的都是平方差误差,只是各部分误差权重设计的不同,想想这里的设计技巧,是精华。
容易弄不明白的点:
这里的LOSS算的是什么,首先搞明白什么是对目标负责的cell以及对目标负责的box preditor:
- 对目标负责的cell:一个目标的
truth ground的中心点落在哪个cell里面,那个cell就对这个目标负责。负责的cell才算分类误差。 - 对目标负责的
box predictor:和truth ground的IOU大的那个bbox对它负责。负责的bbox才算坐标误差。
这里贴个图,回想一下: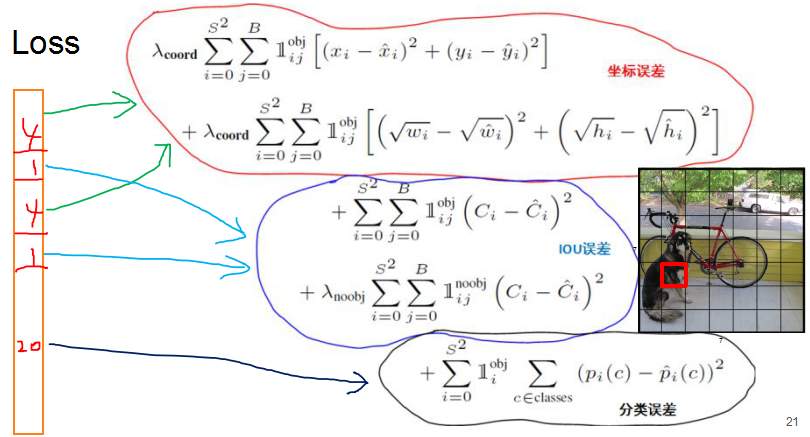
图中有obj标志那个符号的公式只算对图中目标负责的第i个cell的第j个bbox的损失,有noobj标志那个符号的公式只算不对目标负责的bbox的损失。拿坐标误差来说,图中有三个目标(狗,单车,汽车),每个目标有个对它负责的bbox,就有三个bbox算这个坐标误差,其它的bbox都是不算这个坐标误差的。IOU误差是计算三个负责的bbox的误差和不负责的其它的95个bbox的误差(例子一共有98个bbox)。分类误差是针对有目标的三个cell的分类误差,这里也只计算了三次。
思考几个问题:
- 为什么坐标误差用根号?想不懂看YOLOv1论文理解
- 各部分LOSS的权重大小取值有何不同?为什么要取不同的大小?想不起来看【深度学习YOLO V1】深刻解读YOLO V1(图解)
Testing过程和NMS
class-specific confidence score
在testing阶段输入图片,网络会按照与训练时相同的分割方式将测试图片分割成S x S的形状,因此,划分出来的每个网格预测的class信息(就是那20个条件概率)和Bounding box预测的confidence信息相乘,就得到了每个Bounding box的class-specific confidence score,即得到了每个Bounding box预测具体物体的概率和框有多准的信息。
NMS(PPT40页开始,想不起去看)
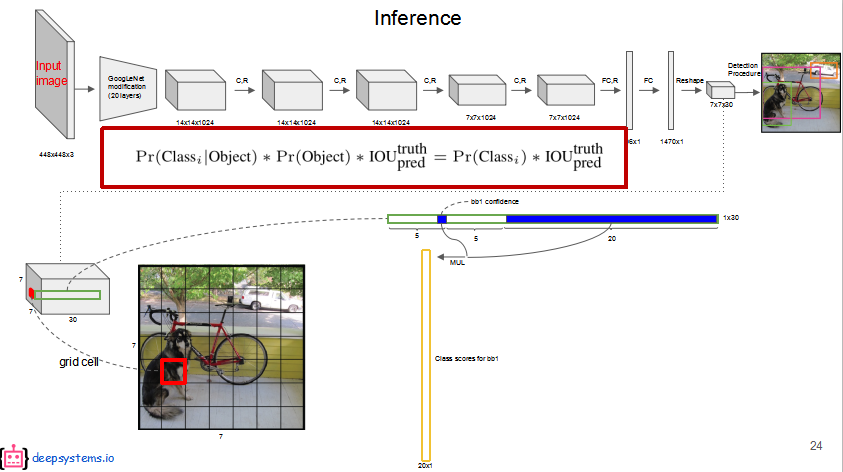
图中每一个横条是一个cell的全部预测值,20个类概率(条件概率)分别和这个cell的每个bbox的confidence相乘之后,一个bbox就有20个新的值,就是图中的一个竖条。所以一共有98个竖条,竖条放在一起每一行代表一个类别的score,对于每一行的score,比如第一行是dog的score,把小于阈值的先设为0,再按照降序排列每个竖条,之后进行NMS:选得分最高的bbox与剩余的非0的bbox进行IOU,大于阈值的的bbox的这个score设为0,再取没删掉中最大的那个做为新的最大的,再与非0的IOU,大于阈值的bbox的这个score设为0,最后这一行可能就剩下几个非零的。对于每一行都做这样的操作,这是对每一类的bbox就行筛选。晒完之后我们竖着看,看98次,就是看每一个bbox了,每个bbox都有20个数,分别代表每个类的得分,经过上面的筛选之后,很多类的得分已经为0了,我们在这20个得分里面找最大的那个类得分,这个类就是这个bbox预测成功的目标。
值得思考的问题
这里就可以问出两个问题:(PPT里提出的)
- 是否会出现,同一grid cell中出现两个相同class的bbox?
- 是否会出现,同一grid cell中出现两个不同class的bbox?
我的理解是,同一个cell里面的两个bbox的c不同,但是乘的是同一组类概率(条件概率),是线性相关的。比如bbox1的c比bbox2的c要大,那么它们和同一组类概率相乘之后对应类别的新值上bbox1永远比bbox2大,也就是bbox1对狗的得分比bbox2对狗的得分大,对猫的得分也是bbox1比bbox2大,其余的类都是我的比你的大,而且如果这组类概率(条件概率)中最大的类别是狗,那么相乘之后bbox1和bbox2的20个新值里面大小顺序还是和相乘之前的条件概率保持一致的,最大的依然是狗。
现在我们考虑NMS的阶段(每个条横着看的阶段),且只考虑这两个bbox(同属一个cell),他们的IOU是一定的:
- 如果这个IOU大于了阈值,bbox1和bbox2的每一行去对比的时候,得分小的那一个(也就是bbox2,因为在每一类上bbox1的得分是bbox2的两倍,看前面的例子)永远是bbox2,它的每一行得分都会被s设为0。最后在单独看bbox的时候(竖着看的时候),bbox2的每个score都是0,所以它不会被判定检测出了哪个目标,此时如果bbox1里有非0的类得分,那它非0得分中的最高得分所指的类别就是它检测出的那一类物体,跟前面说的一样。
- 如果这个IOU小于阈值,在和bbox1的得分比较的时候,bbox2的得分都会被保留下来,这里只考虑它们两个比较,不考虑其它的bbox们。在竖着看的时候,诶,你会发现它们20个类得分里面分最高的肯定属于同一个类别,也就是在同一行,原因上面说了。也就是它们只能检测出同一类物体。
所以这两个问题的答案就出来了,第一个是会,第二个是不会。